【Python】pandas.Grouperで時系列データを楽々groupby!

時系列データを日次・週次・月次(daily, weekly, monthly)でそれぞれ集計・グルーピングするのに便利なpandas.Grouperを紹介します!
動作環境 MacOS Catalina 10.15.7 Python 3.8.2 pandas 1.2.1 VSCode 1.52.1
VSCode拡張機能のJupyterを使用します。 詳細はこちらを参照ください。
pandas.Grouper
データ準備
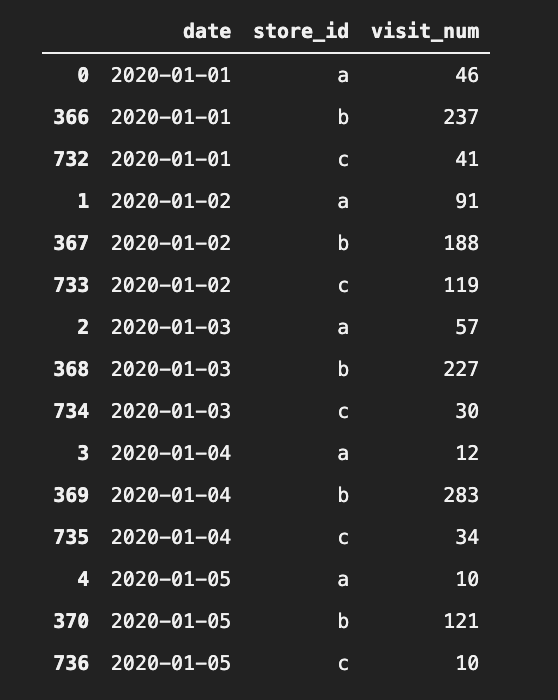
2020年のa店舗、b店舗、c店舗の日次来客数のデータを使用します。
import pandas as pd store_visits_df = pd.read_csv("./csv/store_visits_2020.csv")
このようなデータになっています。

pandas.Grouperを使用する際の注意点として、日付データのカラムは datetime型にしておく必要があります!
store_visits_df.dtypes
date object store_id object visit_num int64 dtype: object
dateカラムはobject型になっていると以下のエラーが発生します。
TypeError: Only valid with DatetimeIndex, TimedeltaIndex or PeriodIndex, but got an instance of 'Index'
以下のようにしてdatetime型に変換しておきましょう。
store_visits_df["date"] = pd.to_datetime(store_visits_df["date"])
日次の集計(daily)
pandas.Grouperの使用例として、まずは日次の集計をしていきます。
日次の来客合計数
store_visits_df.groupby(pd.Grouper(key="date", freq="D")).sum()

■オプション解説
key: groupbyするカラム名
freq: 集計する単位(datetime型のkeyを指定した場合のみ)
インデックスカラムを対象にgroupbyしたい場合は、 level オプションでインデックス名、または数字でレベルを指定可能です。
(
store_visits_df
.set_index(["store_id", "date"])
.groupby(pd.Grouper(level="date", freq="D"))
.sum()
)
■オプション解説
label: groupbyするインデックス名、もしくはレベル(0始まり)
週次の集計(weekly)
freq="W"を指定するだけです!
store_visits_df.groupby(pd.Grouper(key="date", freq="W")).sum()
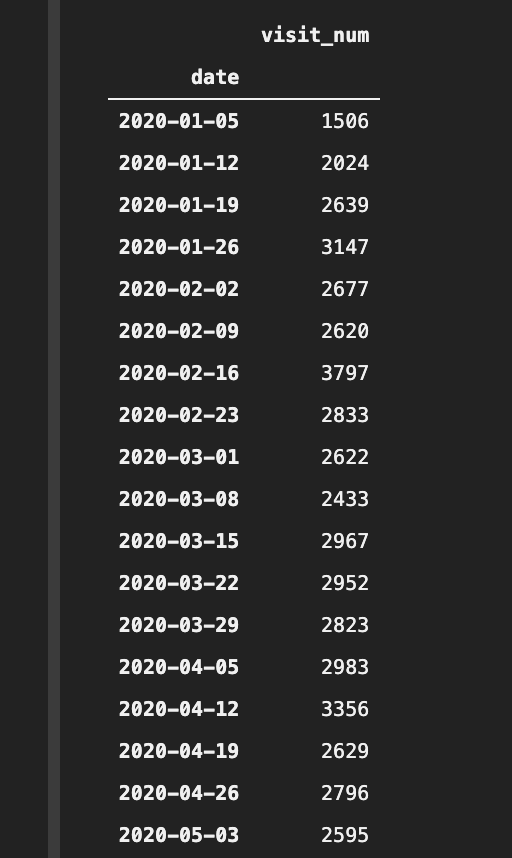
2020-01-01は水曜日。
だが週次の集計データの最初は2020-01-05(日)になっています。
どういうことでしょう?
試しに2020-01-05のグルーピングの中身をみてみます。
store_visits_df.groupby(
pd.Grouper(key="date", freq="W")
).get_group("2020-01-05")
実は、
2020-01-01(水) ~ 2020-01-05(日) の合計が、2020-01-05(日)表記で集計されています。
次の週では、
2020-01-06(月) ~ 2020-01-12(日) の合計が、2020-01-12(日)表記です。
つまり、 月曜から日曜の集計を、日曜で表示しているのです。

例えば、月曜 ~ 日曜の集計で、週始まりの月曜の日付を表示させたい場合は、以下のようにして集計できます。
store_visits_df.groupby(
pd.Grouper(key="date", freq="W-MON", closed="left", label="left")
).sum()

■オプション解説
freq="W-MON": 月曜基準の週 freq="W": "W-SUN"と同義。日曜基準の週
closed="left": 基準を左端にするか、右端にするか(デフォルトは"right" )
label="left": 基準の右側にある基準日を表記するか、左側にある基準日を表記するか
これらの関係性に関しては、以下の記事がわかりやすく紹介してくれています。(resampleに関する記事だが、freq, closed, labelに関しては同じ挙動をします。)
note.com</chttps://blog.hatena.ne.jp/hesma2/hesma2.hatenablog.com/edit?entry=26006613681427048#previewite>

月次の集計(monthly)
store_visits_df.groupby(pd.Grouper(key="date", freq="M")).sum()

■オプション解説
freq="M": 月次(月末日が基準)
月初日で表記させたい場合は、以下のようになります。
store_visits_df.groupby(pd.Grouper(key="date", freq="MS")).sum()

■オプション解説
freq="MS": 月次(月初日が基準)
明示的にclosed, labelで指定も可能です。(環境によってはデフォルトのままclosed="right", label="right" になっている可能性もあります。)
store_visits_df.groupby(
pd.Grouper(key="date", freq="MS", closed="left", label="left")
).sum()
まとめ
時系列データを楽々groupbyするpandas.Grouperを紹介しました!
日次集計
store_visits_df.groupby(pd.Grouper(key="date", freq="D")).sum()
週次集計(月曜始まり)
store_visits_df.groupby(
pd.Grouper(key="date", freq="W-MON", closed="left", label="left")
).sum()
月次集計(月初日)
store_visits_df.groupby(pd.Grouper(key="date", freq="MS")).sum()
pandas.Grouperと同じような処理が可能な、
resampleとpandas.date_rangeで処理を比較してみました ↓