【AWS Glue】スイッチロール先のSparkジョブのメトリクス・ログをSparkUIで見れるようにする
公式ドキュメントだけでは分からない、スイッチロール先のSparkジョブをSparkUIで見れるようにする方法をまとめた
SparkUIサーバーの起動方法
起動方法は2種類(公式ドキュメントより)
ここでは、後者のDockerコンテナをローカル環境に立ち上げる方法を用いる。
スイッチロールしている場合、公式ドキュメントでは分からない
AWS GlueでSparkジョブを作っていてそれらのメトリクス・ログをSparkUIで見れるようにしたい場合、公式のドキュメントの手順に従うだけで実現可能です。
ただし、スイッチロール先の環境でSparkジョブを作っている場合、
- アクセスキー
- シークレットキー
- セッショントークン
を取得しなければ、Dockerコンテナを起動することはできない
スクリプトを作成した
run_sparkui.sh
# 引数をロード
if [ $# = 0 ]; then
echo "第1引数にprofile名を設定してください"
exit 1
fi
PROFILE_NAME=$1
# 既存のコンテナがあれば停止・削除
docker stop sparkui
docker rm sparkui
# アクセスキーとセッショントークンを取得
ROLE_ARN=`aws configure get role_arn --profile ${PROFILE_NAME}`
LOG_DIR=`aws configure get sparkui_log_dir --profile ${PROFILE_NAME}`
if [ -z ${LOG_DIR} ]; then
echo "'~/.aws/config' に 'sparkui_log_dir' が設定されていない可能性があります"
exit 1
fi
AWS_STS_CREDENTIALS=`aws sts assume-role \
--profile ${PROFILE_NAME} \
--role-arn ${ROLE_ARN} \
--role-session-name ${PROFILE_NAME}`
AWS_ACCESS_KEY_ID=`echo "${AWS_STS_CREDENTIALS}" | jq -r '.Credentials.AccessKeyId'`
AWS_SECRET_ACCESS_KEY=`echo "${AWS_STS_CREDENTIALS}" | jq -r '.Credentials.SecretAccessKey'`
SESSION_TOKEN=`echo "${AWS_STS_CREDENTIALS}" | jq -r '.Credentials.SessionToken'`
# コンテナ起動
docker run -itd \
-e SPARK_HISTORY_OPTS="$SPARK_HISTORY_OPTS \
-Dspark.history.fs.logDirectory=$LOG_DIR \
-Dspark.hadoop.fs.s3a.access.key=$AWS_ACCESS_KEY_ID \
-Dspark.hadoop.fs.s3a.secret.key=$AWS_SECRET_ACCESS_KEY \
-Dspark.hadoop.fs.s3a.session.token=$SESSION_TOKEN \
-Dspark.hadoop.fs.s3a.aws.credentials.provider=org.apache.hadoop.fs.s3a.TemporaryAWSCredentialsProvider" \
-p 18080:18080 \
--name sparkui \
glue/sparkui:latest \
"/opt/spark/bin/spark-class org.apache.spark.deploy.history.HistoryServer"
実行手順
0. 前提条件
~/.aws/config にスイッチロール先のプロファイルを作成していること
[default] region = ap-northeast-1 output = json [profile production] role_arn = arn:aws:iam::123456789012:role/ProductionAccessRole source_profile = default
1. Dockerイメージをビルドする
公式ドキュメントに従う
コードサンプルAWS Glueから Dockerfile と pom.xml をダウンロードします。
docker build -t glue/sparkui:latest .
2. イベントログが出力されるS3パスを追加する
~/.aws/config にS3パスを追加する
[default]
region = ap-northeast-1
output = json
[profile production]
role_arn = arn:aws:iam::123456789012:role/ProductionAccessRole
+ sparkui_log_dir = s3a://aws-glue-production-spark-event-logs/
source_profile = default
3. スクリプトを実行
実行権限を与える
chmod + x run_sparkui.sh
第一引数にスイッチロール先のプロファイル名を指定して、実行する
./run_sparkui.sh production
4. SparkUIにアクセス
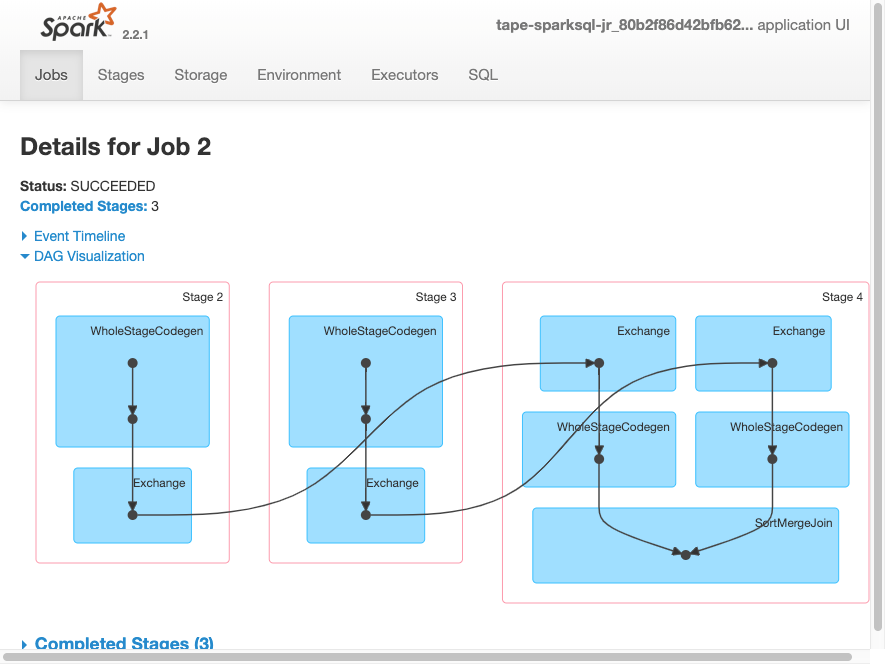 https://docs.aws.amazon.com/ja_jp/glue/latest/dg/images/spark-ui1.pngdocs.aws.amazon.com
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/images/spark-ui1.pngdocs.aws.amazon.com
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/images/spark-ui1.pngdocs.aws.amazon.com
 https://docs.aws.amazon.com/ja_jp/glue/latest/dg/images/spark-ui3.pngdocs.aws.amazon.com
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/images/spark-ui3.pngdocs.aws.amazon.com
【Aurora RDS】文字化けを修正したので、その原因と解決方法をまとめた
Aurora RDSのテーブル内のデータの一部で文字化けが発生してしまい、その修正を行ったのでその原因と解決方法をまとめました!
発生事象
Aurora RDSのテーブルにおいて文字化けが発生。
テーブルの中身をみると ???? に文字化けしていた。
原因
utf8 と utf8mb4 で設定が揺れていたため。
insertは utf8
文字化けの発生したテーブルに対して、毎日データ更新を行うバッチ処理が実行されている。
その際、utf8 にエンコードしてテーブルに書き込んでいた。
engine = create_engine(
myDB,
connect_args={'charset': 'utf8'},
pool_recycle=25200,
)
RDSクラスターは utf8mb4
一方RDSのクラスターのパラメータでは、utf8mb4 に設定されていた。
(というよりも utf8 は設定できない模様)
show variables like 'char%'
そのため、テーブルも utf8mb4 で作成されている。
show create table hogehoge
CREATE TABLE `hogehoge` ( 略 ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
utf8mb4 について
selectは utf8
今回の問題が発生したバリデーションの処理でも、APIでも utf8 になっていた。
まとめるとこんな感じ

何が起きていたのか
utf8 と utf8mb4 の違いは、
utf8は文字を1〜3バイトで表現する。 utf8mb4は文字を1〜4バイトで表現する。
MySQLのutf8とutf8mb4の違いを実際に🍣(スシ)をINSERTして検証する | Playful IT - Designing and Engineering "遊び心"駆動開発 より
4バイトの文字を utf8 でエンコードすると、1バイト欠損してしまう。
解決方法
utf8mb4 に統一することで文字化けを解決。

参考
Renovateおすすめ設定
Renovateの設定をチューニングしたので共有 & 解説をする。
Renovateをより快適に使いこなせ。
- 最終的に設定ファイルはこうなった
- $schema
- timezone
- prHourlyLimitNone
- automergePatch
- schedule
- dependencyDashboard
- ignorePaths
- pip_requirements
- packageRules
- renovateのデバッグ方法
- 参考
最終的に設定ファイルはこうなった
それぞれの設定について解説する。
{ "$schema": "https://docs.renovatebot.com/renovate-schema.json", "extends": [ "config:base", ":timezone(Asia/Tokyo)", ":prHourlyLimitNone", ":automergePatch" ], "schedule": ["after 9am on monday", "before 12am on monday"], "dependencyDashboard": true, "ignorePaths": [ "src/i_want_to_ignore/*", "Dockerfile", "docker-compose.yml", ], "pip_requirements": { "fileMatch": [ "src/i_want_to_check/requirements_dev.txt", "src/mee_too/requirements_dev.txt" ] }, "packageRules": [ { "groupName": "boto3", "matchPackagePatterns": [ "boto3", "botocore" ] } ] }
$schema
https://docs.renovatebot.com/config-presets/#organization-level-presets
"$schema": "https://docs.renovatebot.com/renovate-schema.json",
VSCodeで補完が効くようになる。地味に便利。

timezone
https://docs.renovatebot.com/presets-default/#timezoneltarg0gt
https://docs.renovatebot.com/configuration-options/#timezone
"extends": [ ":timezone(Asia/Tokyo)", ]
デフォルトはUTCになっている。
prHourlyLimitNone
https://docs.renovatebot.com/presets-default/#prhourlylimitnone
"extends": [ ":prHourlyLimitNone", ]
1時間で作成できるPR数の上限を無くす。
デフォルトだと1時間に2個までしかPRが作成されない。
単発で来るよりも、一気に来て一気に捌きたいのでこの設定に。
(好みに合わせて設定しよう)
また、renovateが作成できるPR数(リポジトリ単位)にも上限があり、デフォルトでは20個まで。
https://docs.renovatebot.com/configuration-options/#prconcurrentlimit
automergePatch
https://docs.renovatebot.com/presets-default/#automergepatch
"extends": [ ":automergePatch" ]
パッチなら自動でマージする。
最低でも1人のApproverが必要な場合、renovate-approveを入れておくと良い。
CODEOWNERS でApproverを自動設定している場合renovate-approveは動かないので、CODEOWNERSからrenovateがみているファイルの設定を外すとおそらく動く(未検証)
Due to a GitHub limitation, it is not possible to assign any app like this one as a CODEOWNER, so unfortunately this bot won't work that way if you have CODEOWNERS set up.
CODEOWNERSからrenovateがみているファイルの設定を外す
- * @<username> # ホワイト形式の記載しかできない + *.py @<username>
schedule
https://docs.renovatebot.com/configuration-options/#schedule
"schedule": ["after 9am on monday", "before 12am on monday"],
月曜の9am ~ 12amにPRが作成される。 (通知が来ることやautomergeされることも考えて、営業時間内にしている)
ここも好みに合わせて、日曜夜などに設定するのもアリ。
デフォルトでUTCになっているので注意。(timezoneを設定せよ)
dependencyDashboard
https://docs.renovatebot.com/configuration-options/#dependencydashboard
"dependencyDashboard": true,
issueにrenovateのダッシュボードが作成される。
溜まっているPRや、表面化していないアップデートなど一覧化できる。
↓ 作成されるダッシュボードの例
https://github.com/shibayu36/typescript-cli-project/issues/17
Edited/Blocked
手動で編集したPRの一覧
チェックボックスにチェックすることで、最初からやり直すことができる

Open
作成されたPR一覧
チェックボックスにチェックすることで、retry/rebaseすることができる

Ignored or Blocked
クローズされたPR一覧
チェックボックスにチェックすることで、再作成できる

Awaiting Schedule
スケジュールによる作成を待っているPR一覧
チェックボックスにチェックすることで、スケジュール時に作成されないようにすることができる

renovate再実行
一番下のチェックボックスにチェックすることで、renovateのクロールを再度実行できる

ignorePaths
https://docs.renovatebot.com/configuration-options/#ignorepaths
"ignorePaths": [ "src/i_want_to_ignore/*", "Dockerfile", "docker-compose.yml", ]
renovateがチェックしないようにする。
パス指定、ファイル名指定などできる。
pip_requirements
https://docs.renovatebot.com/modules/manager/pip_requirements/
"pip_requirements": { "fileMatch": [ "src/i_want_to_check/requirements_dev.txt", "src/mee_too/requirements_dev.txt" ] }
requirements.txt からファイル名を変更した場合、pip_requirements で指定できる。
fileMatch では正規表現が使える。
https://docs.renovatebot.com/modules/manager/#file-matching
packageRules
https://docs.renovatebot.com/configuration-options/#packagerules
"packageRules": [ { "groupName": "boto3", "matchPackagePatterns": [ "boto3", "botocore" ] } ]
いくつかのパッケージをまとめてPRを作成して欲しい場合、この設定をすると良い。
renovateのデバッグ方法
設定したけどなんか動いてないかも?という時に見るべきもの
https://app.renovatebot.com/dashboard
ここからrenovateのログを確認できる。
参考
【Sphinx】Pythonドキュメントをdocstringから良い感じに作成する
Pythonのドキュメント・リファレンスをdocstringの内容から良い感じに生成してくれる、Sphinxの簡単な使い方を紹介します!
動作環境
Python 3.7.4 Sphinx 1.7.6
完成イメージ
ドキュメントのデザインはこんな感じです。
画像では1ページしかありませんが、モジュールが複数あればモジュールごとにページが作成され、左のリンク集から辿ることができるようになります!

手順
1. Sphinxをインストール
pip install sphinx
2. プロジェクト作成
mkdir docs sphinx-quickstart docs
対話形式でたくさんの質問が来るが、全てそのままEnterでOKです(あとで設定ファイルを編集します)
ただし、 Project name と Author name(s) は入力が必要になります。
> Project name: mi-restapi > Author name(s): kizuki-engineer
3. 設定の編集
conf.py を編集
# 以下のコメントを外し、conf.pyから見たルートディレクトリへのパスを設定します(ここでは../) - # import os - # import sys - # sys.path.insert(0, os.path.abspath('.')) + import os + import sys + sys.path.insert(0, os.path.abspath('../'))
conf.py に拡張機能を追加
- extensions = [] + extensions = [ + "sphinx.ext.autodoc", + "sphinx.ext.napoleon", + ]
autodocの設定を拡張して、プライベートメソッドもドキュメントに含めるように設定します。
conf.py に以下を追加
+ autodoc_default_flags = [ + 'members', + 'private-members' + ]
4. ドキュメント作成
pyファイルからrstファイルを生成
今回はモジュールごとにドキュメントを生成したいので、 -e を指定します。
-E, --no-headings Do not create headings for the modules/packages. This is useful, for example, when docstrings already contain headings.
sphinx-apidoc -e -f -o ./docs .
その他のオプションは以下のリンクを参照ください。
トップページの設定をするため、 index.rst を編集
今回は modules.rst に全てのモジュールがまとまっていたため、modulesを設定しました。
.. toctree::
:maxdepth: 2
:caption: Contents:
+ modules
ビルドを実行します。
sphinx-build ./docs/ ./docs/_build/
成功すると、./docs/_build/ の下にindex.htmlが生成されます!
質素なページなので、スタイルを変更していきます。
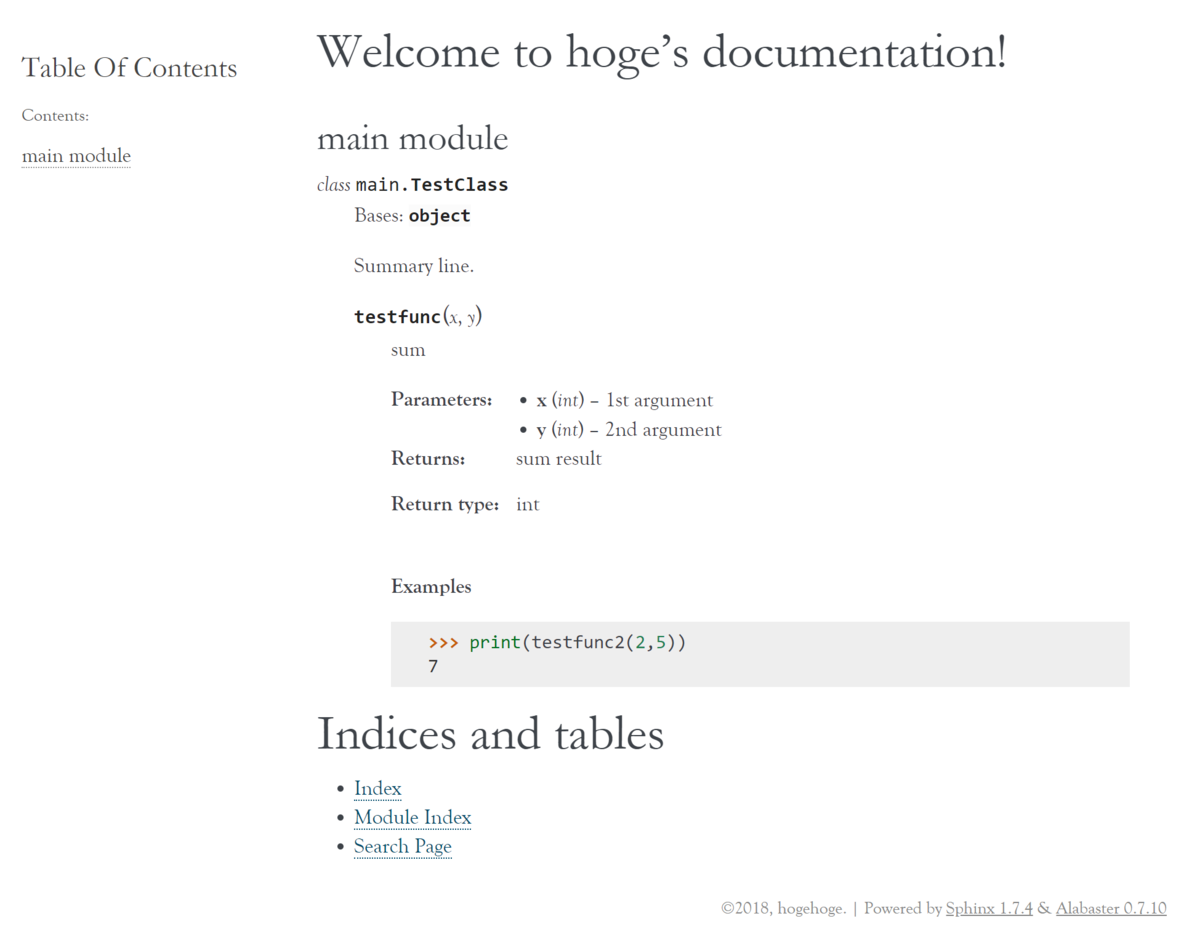
スタイルの変更
sphinx_rtd_themeをインストール、適用していきます。
pip install sphinx_rtd_theme
conf.py を編集します。
- html_theme = 'alabaster' + html_theme = 'sphinx_rtd_theme'
再度ビルドすると、最初の完成イメージのようなデザインのページが出来上がります!
sphinx-build ./docs/ ./docs/_build/
napoleonのエラー
docstringの書き方によっては、napleonのパース時にwarningが発生してしまいます。
例えば以下のような感じのエラーです。
WARNING: Definition list ends without a blank line; unexpected unindent.
以降では、実際に筆者がハマったエラーとその修正方法を紹介していきます。(例に挙げてるソースコードは雑な再現です)
また、筆者のチームではGoogleスタイルのDocstringを採用しています。
【エラーケース1】dictの書き方が不正
Before
def get_user_detail(user_id): """ ユーザーの詳細情報を取得する Returns: { "ユーザーID": str, "ユーザー名": str, "電話番号": str, "メールアドレス": str, "住所": str, } """
After
def get_user_detail(user_id): """ ユーザーの詳細情報を取得する Returns: dict: ユーザーの詳細情報:: { "ユーザーID": str, "ユーザー名": str, "電話番号": str, "メールアドレス": str, "住所": str, } """
【エラーケース2】 * の使い方が不正
展開で使う * をdocstringで使ってしまうと、napoleonはそれを強調と認識してしまいます。
閉じる * がないのでwarningを出してしまう、というわけです。
before
def create_user_df(args): """ hogehoge Args: user_df: [*args, "hogehoge"] """
after
def create_user_df(args): """ hogehoge Args: user_df: 以下のカラムを持つdf:: [args, "hogehoge"] """
【エラーケース3】不正なセクション
napoleonがサポートしてないセクションを設定してしまうとNG。

before
def get_sales_data(store_id, start_date, end_date): """ 期間内の店舗売り上げを取得する columns: 日付: date 売上: int 出費: int 来客数: int 平均単価: float """
after
def get_sales_data(store_id, start_date, end_date): """ 期間内の店舗売り上げを取得する Returns: dict: 店舗売り上げのデータ:: 日付: date 売上: int 出費: int 来客数: int 平均単価: float """
参考サイト
【MySQL】クエリチューニング・Explainテクニック

MySQLのパフォーマンスチューニングで重要な、Explainを使ったクエリ調査に関するテクニックをまとめてみました。
Explain結果のカラム概要(一部)
- key_len
- 利用したキーの長さ(バイト)
- rows
- 実行計画上で検査するレコード数
- 統計情報と実際のデータの分布に解離がある場合、実際に検査するレコード数とは解離する
- extra
- 後述
Extraについて
公式リファレンス
よくあるやつで注意すべきものをピックアップ
Using filesort
最後に追加でクイックソートが発生している
ソート対象の行が多いと遅くなる
結果レコード数が多い場合注意が必要
Using temporary
ソートのために一時テーブルを利用している
考えられるケース
- 集計関数を利用した結果を対象にしたソート
- 昇順と降順が混じったソート
where句での絞り込み後の結果サイズによっては遅くなる
インデックスを指定してExplain
インデックスの候補が複数ある場合、それぞれでExplainして比較できる。
複数指定可能で、その中から最適と思われるインデックスが選択される。
explain select c1 from t1 use index(idx_hogehoge) where <略>
実際にqueryの実行もできる
select c1 from t1 use index(idx_hogehoge) where <略>
実際の検査レコード数を確認
explainのrowsで確認できるが、あくまで統計情報からの予測でしかない。
実際に確認した方が無難。
Handler_% ステータス変数で確認することが可能。
ステータス変数とはMySQLの内部ステータスで、セッションスコープとグローバルスコープがある。
それぞれ show session status, show global status で表示させられる。
また、 flush status でクリア可能(セッションスコープ変数のみクリアされる模様)
flush status; select c1 from t1 where <略>; show session status like "Handler_%";
Handler_read_next が検査レコード数。
explainのrowsと実際の検査レコード数が解離している場合
統計情報を疑うべし
統計情報を更新してみる
analyze table t1;
そのほかにExplainで可能なこと
- delete, insert, replace, updateもexplainが実行できる
explain format=jsonとすると結果がjson形式で返ってくるexplain for connection nのnにshow processlistのidを指定することで、実行中のステートメントをexplain可能
クエリのボトルネックを調査
show profile でクエリのどの工程に時間がかかっているのか調査できる
MySQL5.6以降では非推奨らしい
-> performance_schemaが推奨
利用方法
プロファイルを実行するように設定
set session profilling = 1;
直前のクエリをプロファイルする場合
show profile;
過去のクエリをプロファイルする場合
show profiles;
show profile for query <id>;
S3のバケットポリシーで特定のユーザー・ロールを除いてDenyしたい【NotPrincipal・Condition】

S3のバケットポリシーで特定のユーザー・ロールを除いてDenyしたい時の設定方法を、失敗例を添えてご紹介します。
スイッチロールをしている環境での設定方法も紹介しています。
【失敗例】自分がポリシーを変更できなくなった(アホ)
S3のバケットポリシーのベストプラクティスとしては、必要最低限のアクションを必要最低限のユーザー・ロールに設定することだと思います。
しかし、そこまでガチガチにやるのは面倒な場合、これだけはというアクションを拒否しておくというやり方もあります。
そこで私は、以下のように4つのアクションを拒否したバケットポリシーを設定しました。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Deny", "Principal": "*", "Action": [ "s3:DeleteBucketPolicy", "s3:PutBucketAcl", "s3:PutBucketPolicy", "s3:PutEncryptionConfiguration", "s3:PutObjectAcl" ], "Resource": [ "arn:aws:s3:::test-bucket-policy-deny", "arn:aws:s3:::test-bucket-policy-deny/*" ] } ] }
すると、自分もポリシーが変更できなくなってしまいました。
アホですね☆

こうなってしまったら、バケットを削除して作り直すか、ルートユーザーを管理している方に頭を下げて修正してもらいましょう。
(私は土下座して修正してもらいました)
NotPrincipalで特定のユーザー・ロールを除いて拒否する
先ほどは Principal: * に設定していたため、全てのユーザー・ロールで拒否されてしまっていました。
なので、 NotPrincipal を使って特定のユーザー・ロールを除いて拒否するようにしましょう。
ただ、公式では NotPrincipal を使うのはあまり推奨されていませんでした。
ご利用は計画的に。

除きたいユーザーのARNをNotPrincipalに設定します。
公式によると、親アカウントを超える権限を持つことはできないため、ルートユーザーもNotPrincipalに設定する必要があるようです。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Deny", "NotPrincipal": { "AWS": [ "arn:aws:iam::444455556666:user/Bob", "arn:aws:iam::444455556666:root" ] }, "Action": [ "s3:DeleteBucketPolicy", "s3:PutBucketAcl", "s3:PutBucketPolicy", "s3:PutEncryptionConfiguration", "s3:PutObjectAcl" ], "Resource": [ "arn:aws:s3:::test-bucket-policy-deny", "arn:aws:s3:::test-bucket-policy-deny/*" ] } ] }
これで設定ができたと思われます。
ただ私の環境ではスイッチロールでこのS3のあるアカウントにアクセスしていたため、この設定ではダメなようでした....
Conditionでスイッチロール先のロールを除いて拒否する
スイッチロール先にロールを除きたい場合、NotPrincipalではなくConditionを使うことで実現可能でした。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Deny", "Principal": "*", "Action": [ "s3:DeleteBucketPolicy", "s3:PutBucketAcl", "s3:PutBucketPolicy", "s3:PutEncryptionConfiguration", "s3:PutObjectAcl" ], "Resource": [ "arn:aws:s3:::test-bucket-policy-deny", "arn:aws:s3:::test-bucket-policy-deny/*" ], "Condition": { "StringNotLike": { "aws:userid": "<role-id>:*" } } } ] }
この設定でスイッチロール先のロールを除いてDenyを設定することができました!!
条件演算子(StringNotLikeなど)については ↓ こちら
ポリシー変数に使用可能なリクエスト情報(aws:useridなど)については ↓ こちら
ロールIDの取得はawsコマンドで可能です
$ aws iam get-role --role-name Test-Role
複数条件でConditionを使いたい場合は ↓ こちらを参照
【Pandas】2つのDataFrameが一致していることをテストする(assert_frame_equel)

DataFrameを返す関数のテストを書く時に、期待されるDataFrameと返り値のDataFrameをどう比較したものか頭を悩ませたことはありませんか?
私は悩んだ結果、for文で1つ1つの要素を比較するというなんとも面倒なことをした経験があります。
↓ こんな感じ
# a_df と b_df の各要素が一致することをテスト for index, row in a_df.iterrows(): for column in a_df.columns: assert row[column] == b_df.at[index, column]
その後、2つのDataFrameを良い感じに比較してくれる assert_frame_equel を偶然見つけてからはだいぶテストを書くのが楽になりました。
この記事ではその assert_frame_equel を紹介していきます。
- データ準備
- assert_frame_equelの使い方
- [chack_dtype=False] 型の比較をしない
- [check_like=True] インデックス・カラムの順序を無視する
- その他のオプション
- Index, Seriesを比較する
動作環境 MacOS Catalina 10.15.7 Python 3.8.6 pandas 1.2.1 VSCode 1.52.1
VSCode拡張機能のJupyterを使用します。 詳細はこちらを参照ください。
データ準備
他の記事で良く使っているデータをDataFrameにして使おうと思います。
2020年のa店舗、b店舗、c店舗の日次来客数のデータです。
import pandas as pd a_df = pd.read_csv("./csv/store_visits_2020.csv")

assert_frame_equelの使い方
from pandas.testing import assert_frame_equal b_df = a_df.copy() assert_frame_equal(a_df, b_df)
一致している場合 → None
print(assert_frame_equal(a_df, b_df)) > None
一致していない場合 → 例外が発生
# 列を増やす b_df = a_df.copy() b_df["hoo"] = "bar" assert_frame_equal(a_df, b_df)
--------------------------------------------------------------------------- AssertionError Traceback (most recent call last) <ipython-input-11-e8e4f3008e7b> in <module> 2 b_df["hoo"] = "bar" 3 ----> 4 assert_frame_equal(a_df, b_df) [... skipping hidden 1 frame] ~/.pyenv/versions/3.8.2/lib/python3.8/site-packages/pandas/_testing.py in raise_assert_detail(obj, message, left, right, diff, index_values) 1071 msg += f"\n[diff]: {diff}" 1072 -> 1073 raise AssertionError(msg) 1074 1075 AssertionError: DataFrame are different DataFrame shape mismatch [left]: (1098, 3) [right]: (1098, 4)
どこが違うのか教えてくれるので、デバッグにも便利です。
上のエラーではDataFrameのshapeが違うと言ってますね。
a_df、上でいう [left] は 1098行3列に対して、
b_df、上でいう [right] は1098行4列
left, rightは引数で与えられたDataFrameのうちどちらに該当しているかを示しています。
assert_frame_equelはTrue, Falseを返すものではないので、if文などで使うことはできません。
基本的にテストで使うものだと思われます。
また、さすがにこの間違え方をするのは私くらいだと思いますが、
# × assert assert_frame_equal(a_df, b_df) is None # ○ assert_frame_equal(a_df, b_df)
です。
(まあ上でも問題はないと思いますが...)
[chack_dtype=False] 型の比較をしない
デフォルトはTrue
# 型を変える b_df = a_df.copy() b_df["visit_num"] = b_df["visit_num"].astype(float) assert_frame_equal(a_df, b_df)
エラーが発生します
AssertionError: Attributes of DataFrame.iloc[:, 2] (column name="visit_num") are different Attribute "dtype" are different [left]: int64 [right]: float64
型の違いまでチェックしなくて良い場合、 check_dtype=False を設定してあげましょう。
ただし、日付の型で同じことをやりたい場合、 check_datetimelike_compat の指定をすることでうまくできるかもしれません。
# 型を変える b_df = a_df.copy() b_df["visit_num"] = b_df["visit_num"].astype(float) assert_frame_equal(a_df, b_df, check_dtype=False)
[check_like=True] インデックス・カラムの順序を無視する
デフォルトはFalse
# カラムの順番を入れ替える b_df = a_df.copy() b_df = b_df[["date", "visit_num", "store_id"]] assert_frame_equal(a_df, b_df)
カラムの順番が違うと怒られます
AssertionError: DataFrame.columns are different DataFrame.columns values are different (66.66667 %) [left]: Index(['date', 'store_id', 'visit_num'], dtype='object') [right]: Index(['date', 'visit_num', 'store_id'], dtype='object')
カラムの順番を合わせてから比較することもできますが、
check_like=Trueを指定することで順序を無視することが可能です。
# カラムの順番を入れ替える b_df = a_df.copy() b_df = b_df[["date", "visit_num", "store_id"]] assert_frame_equal(a_df, b_df, check_like=True)
インデックスの場合も同様です。
# インデックスの順番を入れ替える b_df = a_df.copy() b_df = b_df.sort_values("visit_num") assert_frame_equal(a_df, b_df, check_like=True)
ただし、インデックスを振り直してしまうとうまくいかないので注意が必要です。
# インデックスの順番を入れ替える b_df = a_df.copy() b_df = ( b_df.sort_values("visit_num") .reset_index(drop=True) ) assert_frame_equal(a_df, b_df)
AssertionError: DataFrame.iloc[:, 0] (column name="date") are different DataFrame.iloc[:, 0] (column name="date") values are different (99.6357 %) 以下略
その他のオプション

他のオプションに関しては、使ったことがない or 使い方がわからないので、公式のリファレンスを翻訳したのを載せておきます。
Index, Seriesを比較する
Indexを比較する場合、assert_index_equel
Seriesを比較する場合、assert_series_equel
が使えます。