【Postman】Cognitoのアクセストークン・IDトークン取得を自動化する

PostmanでAPIのテストをする際に、毎回何かしらの手段でCognitoのトークンを取得してAuthorizationヘッダーにコピペするのはとても面倒です。
そのトークンを楽に取得して複数のAPIで使いまわせるようにできないか、試してみたので共有します。
動作環境 MacOS Catalina 10.15.7 Postman 8.0.4
これまではどうしていたのか
サービスにログインした後、開発者ツールを呼び出してLocalStorageからトークンをコピー。
その後Postmanの環境変数を上書きする、というなんとも面倒なことをしていました。


OAuth2.0でトークンを取得する
まずはCognito側の設定を行います。
アプリクライアントの作成


アプリクライアントの設定
アプリの統合 > アプリクライアントの設定
- 有効なIDプロバイダのCognito User Poolにチェック
- コールバックURLを
https://https://oauth.pstmn.io/v1/callbackに設定 - OAuthフローで
Implicit grantにチェック - OAuthスコープで
openidにチェック(アプリで必要な情報があれば他にもチェック)

ドメイン名の設定
アプリの統合 > ドメイン名

PostmanのOAuth2.0でトークンを取得
AuthorizationタブでOAuth2.0を選択、Configure New TokenでCognitoユーザープールのアプリクライアントの情報を入力
- Token Nameは任意の名前を入力
- Grant Typeは
Implicit - Callback URLの下の「Authorize using browser」にチェック
- Auth URLに設定したドメイン名 + authorizeのURLを入力
- ClientIDにアプリクライアントIDを入力(環境変数に入れることを推奨されます)
- Scopeに
openidを設定

Get New Access Token をクリック
ブラウザに新しいタブが作られるので、ユーザープールに登録されたユーザーでログインすることでトークンが取得できます。

MANAGE ACCESS TOKENSにトークンが追加されます

Access Token以外にも、いくつかの項目が同時に取得されています。
- Token Type
- id_token
- expires_in
最後に、User Tokenをクリックすることで自動的にリクエストヘッダーにアクセストークンが追加されます!

もう少し便利にするために
このトークン取得 -> 追加を全てのリクエストで行うのは面倒なので、Collectionsで設定してあげましょう。

リクエストと同様にAuthorizationタブがあるので、ここからトークンを取得 -> 追加を行いましょう。
そうすることで、このCollection内のリクエスト全てのヘッダーにアクセストークンが追加されます!!
アクセストークンじゃなくてIDトークンを自動で追加したいんだけど・・・
この方法で追加されるのはアクセストークンで、IDトークンの方は選択できません...
取得自体は楽にできたけど、IDトークンを使うにはコピペが必要です、残念ながら...
私自信IDトークンが必要だったので、他の手段がないかネットを漁りました。
結論から言うと見つかりませんでした...
以降は、ダメだった方法を、なぜダメだったのか紹介します。
IDトークンをいい感じに取得したい!
【ダメだった】MANAGE ACCESS TOKENSからIDトークンを選択して貼り付けられないの!?
同じような問合せやIssueが存在していましたが、まだ解決はされていないようです。(2021年2月7日時点)
【できなくもない】Cognitoのトークンエンドポイントから取得して環境変数にscriptで格納する
前提として、Cognitoユーザープールのアプリクライアントの設定を変更する必要があります。
具体的には、OAuthフローで Client credentials を許可します。
私の環境では Client credentials への変更は許可されておらず断念しましたが...

PostmanでCognitoのトークンエンドポイントへのリクエストを作成します。
トークンエンドポイントのURLやパラメータについては下記URLを参照ください。

リクエストの結果からトークンを取得して環境変数に格納するスクリプトを、Tests に記述します。
本来はテストに使われますが、リクエストの後に実行されることから Post-request Scripts として使用することも可能です。

ここまでできるのであれば、Pre-request Scriptsでトークンの有効期限チェック -> トークン取得 -> 環境変数格納を実装することも可能かもしれません。
【ダメだった】AuthorizationタブのOAuth2.0でできることを、自前のリクエストとスクリプトで再現する
OAuthフローで Client credentials を許可できなかった私。
次に考えたのは、AuthorizationタブのOAuth2.0でできることを、自前のリクエストとスクリプトで再現することでした。
まずは認可エンドポイントへのリクエストを作ります。
認可エンドポイントについてはこちら

このリクエストを実行すると、ブラウザの新規タブが立ち上がる。
そこでログインが成功すると、アクセストークンやIDトークンがレスポンスとして帰ってくる。
それをTestsのスクリプトで環境変数に格納すれば...
なんてことを妄想していました。
結果としては、ログインを促すポップアップなりブラウザなりが立ち上がりませんでした。


他にもPre-request Scriptsでリクエストを送ってみたりしましたが、結果として実現はなりませんでした。(技術や知識不足も否めませんが...)
まとめ
【Python】pandas.Grouper・resample・pandas.date_rangeの処理を比較する

時系列データを扱う際によく使われる、以下の3つの処理を日次・週次・月次(daily, weekly, monthly)で比較してみます!
どこが同じで、どこが違うのかを確認していきます!
【比較対象】
- pandas.Grouper
- resample
- pandas_date_range
pandas.Grouperについてはこちらの記事で紹介しています。
動作環境 MacOS Catalina 10.15.7 Python 3.8.6 pandas 1.2.1 VSCode 1.52.1
VSCode拡張機能のJupyterを使用します。 詳細はこちらを参照ください。
データ準備
2020年のa店舗、b店舗、c店舗の日次来客数のデータを使用します。
import pandas as pd store_visits_df = pd.read_csv("./csv/store_visits_2020.csv")

pandas.Grouper、pandas.resample共に、日付データのカラムは datetime型 にしておく必要があります。
store_visits_df.dtypes
date object store_id object visit_num int64 dtype: object
dateカラムはobject型になっていると以下のエラーが発生します。
TypeError: Only valid with DatetimeIndex, TimedeltaIndex or PeriodIndex, but got an instance of 'Index'
以下のようにしてdatetime型に変換しておきましょう。
store_visits_df["date"] = pd.to_datetime(store_visits_df["date"])
また、resampleでは日付カラムをインデックスに設定する必要があります。
store_visits_df = store_visits_df.set_index("date")
日次の処理(daily)
pandas.Grouperの場合
grouper_daily_df = store_visits_df.groupby(
pd.Grouper(level="date", freq="D")
).sum()
grouper_daily_df

resampleの場合
resample_daily_df = store_visits_df.resample("D").sum()
resample_daily_df
こちらも同じ結果に!
全く同じDataFrameであることを、 assert_frame_equal を使用して確認します。
from pandas.testing import assert_frame_equal print(assert_frame_equal(grouper_daily_df, resample_daily_df)) > None
assert_frame_equal についてはこちら ↓
日次では、pandas.Grouperとresampleが同じ処理をしていることがわかりました。
コード的にはresampleの方がシンプルになりますね!
pandas.date_rangeの場合
ちょっと毛色が違いますが、date_rangeも比較してみます。
from datetime import date date_range_daily = pd.date_range( start=date(2020,1,1), end=date(2020,12,31), freq="D" ) date_range_daily
結果はこちら ↓
DatetimeIndex(['2020-01-01', '2020-01-02', '2020-01-03', '2020-01-04', '2020-01-05', '2020-01-06', '2020-01-07', '2020-01-08', '2020-01-09', '2020-01-10', ... '2020-12-22', '2020-12-23', '2020-12-24', '2020-12-25', '2020-12-26', '2020-12-27', '2020-12-28', '2020-12-29', '2020-12-30', '2020-12-31'], dtype='datetime64[ns]', length=366, freq='D')
これもpandas.GrouperとresampleのIndexと比較して、同じであることが確認できました。
list(grouper_daily_df.index) == list(date_range_daily) > True list(resample_daily_df.index) == list(date_range_daily) > True
週次の処理(weekly)
月曜 ~ 日曜の1週間を、月曜表示で扱います。
例 【表示】 2020-01-06 【集計】 2020-01-06 ~ 2020-01-12

pandas.Grouperの場合
grouper_daily_df = store_visits_df.groupby(
pd.Grouper(level="date", freq="W-MON", closed="left", label="left")
).sum()
grouper_daily_df

月曜始まりの日曜終わりでちゃんとグルーピングできているかチェックします。
store_visits_df.groupby(
pd.Grouper(level="date", freq="W-MON", closed="left", label="left")
).get_group("2020-01-06")
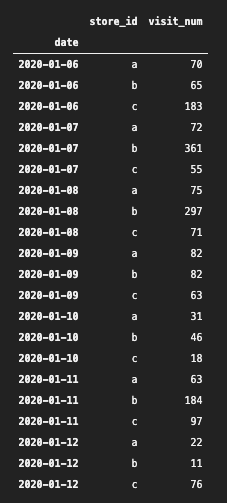
2020-01-06(月)から2020-01-12(日)でグルーピングできていました!
resampleの場合
resample_weekly_df = store_visits_df.resample(
"W-MON", closed="left", label="left"
).sum()
resample_weekly_df
resampleでもpandas.Grouperと同じオプション指定で同じ結果になりました!
念のため、同じDataFrameになったことをチェックします。
print(assert_frame_equal(grouper_weekly_df, resample_weekly_df)) > None
詳細なコードや結果は載せませんが、日曜始まり(freq="W"または"W-SUN")の集計においてもpandas.Grouperとresampleの処理に違いはありませんでした。
pandas.date_rangeの場合
date_range_weekly = pd.date_range(
start=date(2020,1,1),
end=date(2020,12,31),
freq="W-MON"
)
date_range_weekly
結果 ↓
DatetimeIndex(['2020-01-06', '2020-01-13', '2020-01-20', '2020-01-27', '2020-02-03', '2020-02-10', '2020-02-17', '2020-02-24', '2020-03-02', '2020-03-09', '2020-03-16', '2020-03-23', '2020-03-30', '2020-04-06', '2020-04-13', '2020-04-20', '2020-04-27', '2020-05-04', '2020-05-11', '2020-05-18', '2020-05-25', '2020-06-01', '2020-06-08', '2020-06-15', '2020-06-22', '2020-06-29', '2020-07-06', '2020-07-13', '2020-07-20', '2020-07-27', '2020-08-03', '2020-08-10', '2020-08-17', '2020-08-24', '2020-08-31', '2020-09-07', '2020-09-14', '2020-09-21', '2020-09-28', '2020-10-05', '2020-10-12', '2020-10-19', '2020-10-26', '2020-11-02', '2020-11-09', '2020-11-16', '2020-11-23', '2020-11-30', '2020-12-07', '2020-12-14', '2020-12-21', '2020-12-28'], dtype='datetime64[ns]', freq='W-MON')
pandas.date_rangeでもfreqの指定("W"や"W-MON")は共通でした。
しかし日付リストには違いが出ました。
list(grouper_weekly_df.index) == list(date_range_weekly) > False
差分も出してみます。
set(grouper_weekly_df.index) - set(date_range_weekly) > {Timestamp('2019-12-30 00:00:00', freq='W-MON')}
このことから、pandas.date_rangeは、
start_date から end_date が所属する週のリストを出すのではなく、
start_date から end_date の中にある週の基準日のリストを出す ことがわかります。
月次の処理(monthly)
月初日を基準に集計します。
例 【表示】 2020-01-01 【集計】 2020-01-01 ~ 2020-01-31
pandas.Grouperの場合
月初日を基準とする場合、freq="MS"とします。
(freq="M" では月末日が基準となります)
grouper_monthly_df = store_visits_df.groupby(
pd.Grouper(level="date", freq="MS")
).sum()
grouper_monthly_df

グルーピングも確認します。
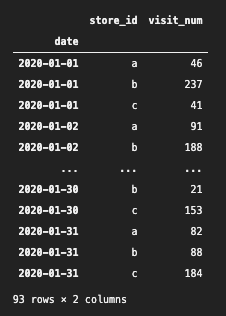
store_visits_df.groupby(
pd.Grouper(level="date", freq="MS")
).get_group("2020-01-01")
resampleの場合
resample_monthly_df = store_visits_df.resample("MS").sum()
resample_monthly_df
月次においても、pandas.GrouperとDataFrameが一致しました!
print(assert_frame_equal(grouper_monthly_df, resample_monthly_df)) > None
pandas.date_rangeの場合
date_range_monthly = pd.date_range(
start=date(2020,1,1),
end=date(2020,12,31),
freq="MS"
)
date_range_monthly
結果 ↓
DatetimeIndex(['2020-01-01', '2020-02-01', '2020-03-01', '2020-04-01', '2020-05-01', '2020-06-01', '2020-07-01', '2020-08-01', '2020-09-01', '2020-10-01', '2020-11-01', '2020-12-01'], dtype='datetime64[ns]', freq='MS')
pandas.Grouperのインデックスと比較します。
list(grouper_monthly_df.index) == list(date_range_monthly) > True
2020-01-01 ~ 2020-12-31 を指定して実行したので同じ結果になりましたが、週次でエッジケースの処理が異なることを考慮すると月次でも同じことが起きるはずです。
試しに、2020-01-02 ~ 2020-12-31 で処理を行ってみます。
date_range_monthly = pd.date_range(
start=date(2020,1,2),
end=date(2020,12,31),
freq="MS"
)
date_range_monthly
結果 ↓
DatetimeIndex(['2020-02-01', '2020-03-01', '2020-04-01', '2020-05-01', '2020-06-01', '2020-07-01', '2020-08-01', '2020-09-01', '2020-10-01', '2020-11-01', '2020-12-01'], dtype='datetime64[ns]', freq='MS')
やはり 2020-01-01 が抜けましたね。この処理の違いには注意が必要そうです。
まとめ
【Python】pandas.Grouperで時系列データを楽々groupby!
時系列データを日次・週次・月次(daily, weekly, monthly)でそれぞれ集計・グルーピングするのに便利なpandas.Grouperを紹介します!
動作環境 MacOS Catalina 10.15.7 Python 3.8.2 pandas 1.2.1 VSCode 1.52.1
VSCode拡張機能のJupyterを使用します。 詳細はこちらを参照ください。
pandas.Grouper
データ準備
2020年のa店舗、b店舗、c店舗の日次来客数のデータを使用します。
import pandas as pd store_visits_df = pd.read_csv("./csv/store_visits_2020.csv")
このようなデータになっています。
pandas.Grouperを使用する際の注意点として、日付データのカラムは datetime型にしておく必要があります!
store_visits_df.dtypes
date object store_id object visit_num int64 dtype: object
dateカラムはobject型になっていると以下のエラーが発生します。
TypeError: Only valid with DatetimeIndex, TimedeltaIndex or PeriodIndex, but got an instance of 'Index'
以下のようにしてdatetime型に変換しておきましょう。
store_visits_df["date"] = pd.to_datetime(store_visits_df["date"])
日次の集計(daily)
pandas.Grouperの使用例として、まずは日次の集計をしていきます。
日次の来客合計数
store_visits_df.groupby(pd.Grouper(key="date", freq="D")).sum()
■オプション解説
key: groupbyするカラム名
freq: 集計する単位(datetime型のkeyを指定した場合のみ)
インデックスカラムを対象にgroupbyしたい場合は、 level オプションでインデックス名、または数字でレベルを指定可能です。
(
store_visits_df
.set_index(["store_id", "date"])
.groupby(pd.Grouper(level="date", freq="D"))
.sum()
)
■オプション解説
label: groupbyするインデックス名、もしくはレベル(0始まり)
週次の集計(weekly)
freq="W"を指定するだけです!
store_visits_df.groupby(pd.Grouper(key="date", freq="W")).sum()
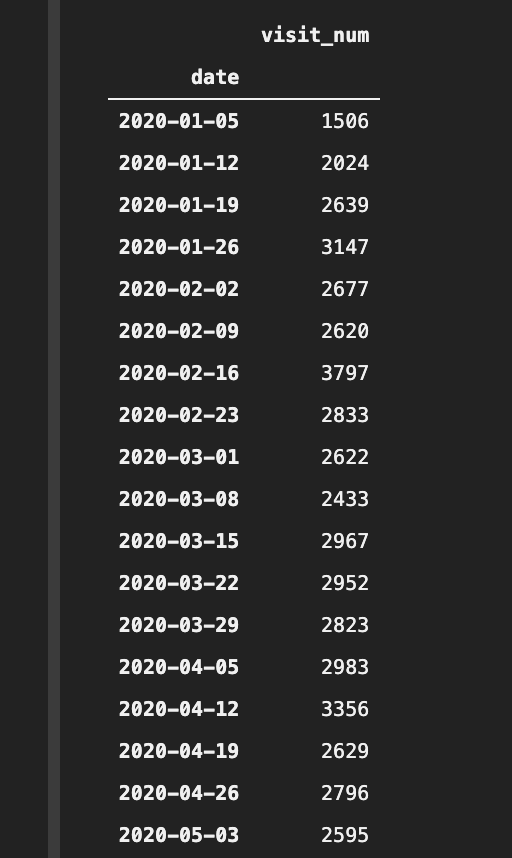
2020-01-01は水曜日。
だが週次の集計データの最初は2020-01-05(日)になっています。
どういうことでしょう?
試しに2020-01-05のグルーピングの中身をみてみます。
store_visits_df.groupby(
pd.Grouper(key="date", freq="W")
).get_group("2020-01-05")
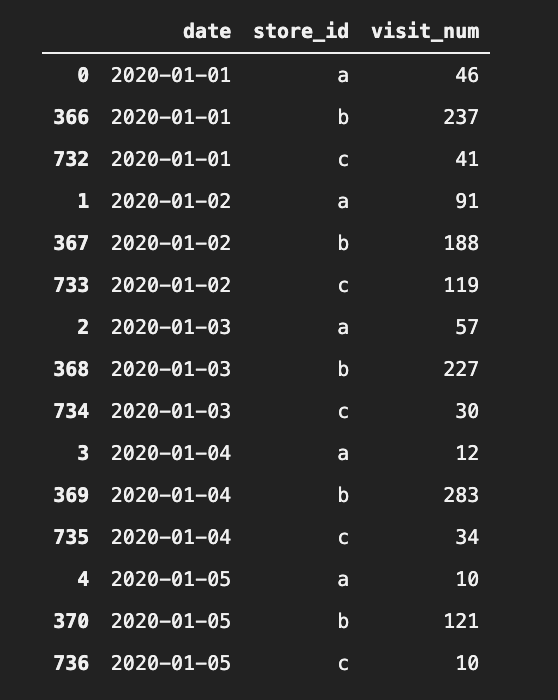
実は、
2020-01-01(水) ~ 2020-01-05(日) の合計が、2020-01-05(日)表記で集計されています。
次の週では、
2020-01-06(月) ~ 2020-01-12(日) の合計が、2020-01-12(日)表記です。
つまり、 月曜から日曜の集計を、日曜で表示しているのです。
例えば、月曜 ~ 日曜の集計で、週始まりの月曜の日付を表示させたい場合は、以下のようにして集計できます。
store_visits_df.groupby(
pd.Grouper(key="date", freq="W-MON", closed="left", label="left")
).sum()
■オプション解説
freq="W-MON": 月曜基準の週 freq="W": "W-SUN"と同義。日曜基準の週
closed="left": 基準を左端にするか、右端にするか(デフォルトは"right" )
label="left": 基準の右側にある基準日を表記するか、左側にある基準日を表記するか
これらの関係性に関しては、以下の記事がわかりやすく紹介してくれています。(resampleに関する記事だが、freq, closed, labelに関しては同じ挙動をします。)
note.com</chttps://blog.hatena.ne.jp/hesma2/hesma2.hatenablog.com/edit?entry=26006613681427048#previewite>

月次の集計(monthly)
store_visits_df.groupby(pd.Grouper(key="date", freq="M")).sum()

■オプション解説
freq="M": 月次(月末日が基準)
月初日で表記させたい場合は、以下のようになります。
store_visits_df.groupby(pd.Grouper(key="date", freq="MS")).sum()
■オプション解説
freq="MS": 月次(月初日が基準)
明示的にclosed, labelで指定も可能です。(環境によってはデフォルトのままclosed="right", label="right" になっている可能性もあります。)
store_visits_df.groupby(
pd.Grouper(key="date", freq="MS", closed="left", label="left")
).sum()
まとめ
時系列データを楽々groupbyするpandas.Grouperを紹介しました!
日次集計
store_visits_df.groupby(pd.Grouper(key="date", freq="D")).sum()
週次集計(月曜始まり)
store_visits_df.groupby(
pd.Grouper(key="date", freq="W-MON", closed="left", label="left")
).sum()
月次集計(月初日)
store_visits_df.groupby(pd.Grouper(key="date", freq="MS")).sum()
pandas.Grouperと同じような処理が可能な、
resampleとpandas.date_rangeで処理を比較してみました ↓
【black】Pythonのソースコードを自動整形!!コードフォーマットで議論するのはもう止めませんか?

Pythonのコードを自動整形するフォーマッター、blackを紹介します。
コードフォーマットをフォーマッターに任せることで、
フォーマットではなくロジックなどに議論を集中することができます。
コードフォーマットで議論するのはもう止めませんか?
blackの特徴
最大の特徴は「設定がほとんどできない」
Pythonのフォーマッターとしては他にも、
- autopep8
- yapf
などありますが、
blackの最大の特徴はなんと言っても、設定がほとんどできないことです。
「え?それじゃあ使い勝手最悪じゃん」
と思ってしまうのも無理はありません。
僕もそう思ってましたから。
「設定がほとんどできない」の利点
設定に関して議論することや悩むことがなくなること
コードのフォーマットには正解がなく、人によって好みがかなり分かれます。
チームで開発する場合これは仕方ない問題であり、
だからこそフォーマッターを導入してコードのフォーマットを統一するのです。
「設定がほとんどできない」ことによって、blackに全てを任せることができます。
blackを半年程度使ってきましたが、「このフォーマットの仕方はいけてないな」と思ったことはほとんどありません。
導入当初、同僚が
「 ' が " にフォーマットされるのだけは許せない」
と言っていましたが、
「blackがそう決めているので仕方ないですね〜」
と議論になるまでもありませんでした。blackに責任転嫁することができるからです。
しばらく使えばblackのフォーマットに慣れますよ、きっと。
blackで設定できること
じゃあ逆に何なら設定できるのか。
pyproject.toml に以下の設定を加えることができます。(詳細は後述)
- 1行の最大の文字数
- 対象のPythonバージョン
- 対象ファイル
- 対象外ファイル
VSCodeで使う場合
VSCodeで使う場合、
- 1行の最大の文字数
の設定のみが可能です。(詳細は後述)
導入方法
次に、blackの導入方法を紹介していきます。
インストール
$ pip install black
設定ファイルを作成
プロジェクトのルートディレクトリ(一番上位の階層)に pyproject.toml を作成します。
[tool.black]
line-length = 88
target-version = ['py37']
include = '\.pyi?$'
exclude = '''
(
/(
\.eggs # exclude a few common directories in the
| \.git # root of the project
| \.hg
| \.mypy_cache
| \.tox
| \.venv
| _build
| buck-out
| build
| dist
)/
| foo.py # also separately exclude a file named foo.py in
# the root of the project
)
'''
1行の最大文字数
line-length = 88
88文字を超えると改行されます。
flake8を導入している場合、設定を合わせると良いでしょう。
Pythonバージョン
target-version = ['py37']
指定したバージョンに対応できる形にフォーマットされます。
対応バージョンは以下。
[py27|py33|py34|py35|py36|py37|py38]
対象ファイル
include = '\.pyi?$'
該当するファイルをフォーマットします。
正規表現で書かれているのでわかりづらいですが、.py .pyi のどちらかのファイルを対象にフォーマットを実行します。
\は.をエスケープする?は直前の文字が0, 1回出現することを示す$は末尾
.pyi はJupyterで作成したファイルに付けられる拡張子です。Jupyterを使わない場合、
include = '\.py$'
で良いと思います。
対象外ファイル
exclude = '''
(
/(
\.eggs # exclude a few common directories in the
| \.git # root of the project
| \.hg
| \.mypy_cache
| \.tox
| \.venv
| _build
| buck-out
| build
| dist
)/
| foo.py # also separately exclude a file named foo.py in
# the root of the project
)
'''
該当するファイルはフォーマットしません。
blackをコマンド実行する
$ black .
カレントディレクトリ(今いるディレクトリ)から下の階層をまとめてフォーマットします。
black コマンドで使える、主なオプションも紹介していきます。
[--check オプション] ルールに従っているかのチェック
blackのルールに従っているかのチェックをする(フォーマットはされません)
$ black --check .
問題なければ↓
All done! ✨ 🍰 ✨ 42 files would be left unchanged.
フォーマット対象があると↓
would reformat /<省略>/black_test.py Oh no! 💥 💔 💥 1 file would be reformatted, 42 files would be left unchanged.
エラーが発生すると↓() の閉じが足りなかったため、エラーが発生していました)
error: cannot format /<省略>/black_error.py: Cannot parse: 25:25: if __name__ == "__main__": Oh no! 💥 💔 💥 41 files would be left unchanged, 1 file would fail to reformat.
[--diff オプション] フォーマットの差分を確認する
フォーマットの差分を確認できます。(これもフォーマットはされません)
$ black --diff .
Githubとかでおなじみに形式で出力されます。- が変更前 + が変更後を示しています。(以下は改行していたのが1行に直されてます)
--- black_test.py 2021-01-17 09:24:56.196098 +0000 +++ black_test.py 2021-01-17 09:25:00.376769 +0000 @@ -7,13 +7,11 @@ def run(): n = int(input()) - tree = [ - Node() for _ in range(n) - ] + tree = [Node() for _ in range(n)] @@ -26,6 +24,5 @@ - would reformat black_test.py All done! ✨ 🍰 ✨ 1 file would be reformatted, 42 files would be left unchanged.
VSCodeでファイル保存時に自動でフォーマットさせる
black コマンドの使い方を紹介しましたが、あれでは毎回コマンドを打ち込んで実行する必要があります。
VSCodeを使っているのであれば、ファイル保存時に自動でフォーマットさせるのがオススメです。
VSCodeの左下の歯車マークから設定を開くか、settings.json に以下の設定を追加します。
{ "python.formatting.provider": "black", "python.formatting.blackArgs": ["--line-length", "88"], "editor.formatOnSave": true }
VSCodeでは最大文字数のみ設定できるようです。
チームで開発している場合、.vscode/settings.json を作成してgit管理することを強くオススメします!
人によって設定が違うと、保存した人が変わる度に毎回同じ箇所がフォーマットされてしまうことがあります...(実体験)
pre-commitでコミット前に毎回チェックさせる
VSCode以外にも、pre-commitを使う選択肢もあります。
1.pre-commitをインストール
$ pip install pre-commit
2.設定ファイル .pre-commit-config.yaml を作成
repos: - repo: https://github.com/ambv/black rev: 19.10b0 hooks: - id: black types: [python] language_version: python3.8
3.pre-commitを設定
$ pre-commit install
まとめ
「設定がほとんどできない」が強みのblackを紹介しました。
- コードのフォーマットに関して議論しなくて済む
- 設定で議論しなくて済む
- VSCodeやpre-commitでフォーマットを自動化できる